
Execution Governance: Controls for Safe Tool Orchestration
Preventing tool-use failures before agents go live || Edition 26

This post is part 8 of the Agentic AI Series — a multi-part exploration of how autonomous systems are reshaping enterprise architecture, governance, and security.
The Short Version
Governance failures materialize at execution. The orchestration layer mediates between agent intent and system actions. Weak controls upstream in planning, coordination, or state management become visible when execution fails.
Tools are identity boundaries. When an agent invokes a tool, it inherits that tool's credentials and permissions. A tool with irreversible write access to your payments system is a payments-system-shaped attack surface.
Design-time controls define safe execution. This post covers schema validation, idempotency, approval gates, error handling, execution budgets, and outcome contracts—each addressing a specific failure mode.
Controls exist to prevent predictable failures. Duplicate execution, inconsistent state, unbounded resource consumption, incorrect outcome assumptions—each has a corresponding control that closes the gap.
Execution controls make accountability concrete. When failures occur, you can trace them to a specific control, a specific configuration, and a specific owner.
The Execution Problem
The previous posts covered how agents perceive context, build plans, coordinate, and manage state. That’s preparation. Execution is where preparation meets reality.
Execution happens through tools. Tool use is the boundary where a structured request becomes an authorized action.
The question is: what controls mediate the handoff from agent intent to system action?
If you’ve read the base architecture post, you know where execution lives: the orchestration layer—everything between the Agent Layer’s intent and the System Layer’s action. Most failures cluster here, because once the agent decides to act, the outcome depends on the controls that govern that handoff.
When AI Acts: The Architecture Behind Agentic AI

The architecture post establishes the foundational layers of an agentic AI system: how context is assembled, how plans are formed, how actions are orchestrated, and how outcomes flow back into the system.
Tools: Anatomy and Autonomy
Tools Are Identity Boundaries. They are the only mechanism through which agents affect the world outside their context window.
A tool is any capability an agent can invoke: an API endpoint, a database query, a file operation, sending a message.
A registered tool is a contract: identity, schema, effects, authorization, and execution controls. Together, these define the control surface that makes tool use governable. A follow-up post on Specifications & Contracts will show an example tool registration format.
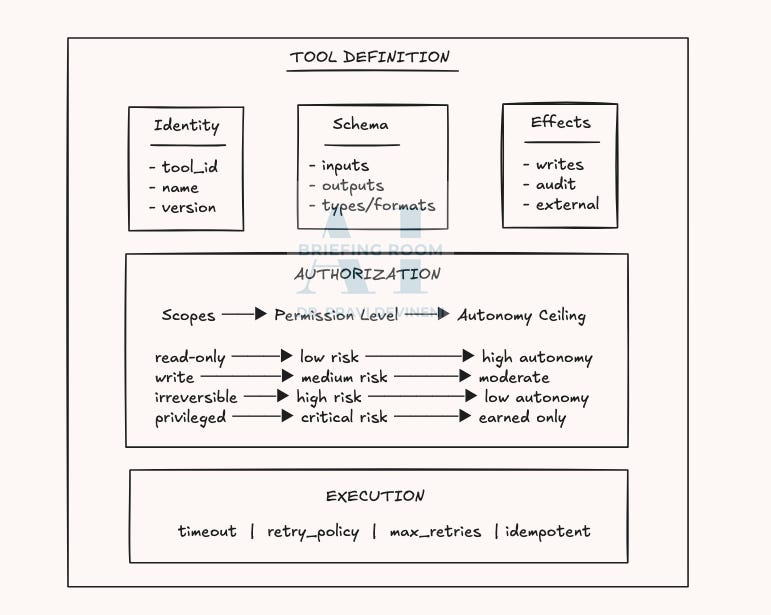
Tool registration is an identity and access management decision, because tool calls execute under real credentials and permissions. Write access turns intent into authority. Authority determines blast radius. Blast radius defines autonomy in practice.
The Autonomy Insight
Permission levels map directly to risk profiles, which set autonomy ceilings. Most tools land in one of five buckets: read-only, write-reversible (rollback-able state changes), write-non-reversible (irreversible writes), execute-reversible (actions with compensation), and execute-non-reversible (point-of-no-return actions). Autonomy should be granted by bucket, because credentials determine blast radius.
Governing Execution: The Control Surface
Execution risk is mostly architectural. The following core set of execution controls covers the most common failure modes, the ones responsible for the largest share of preventable risk.
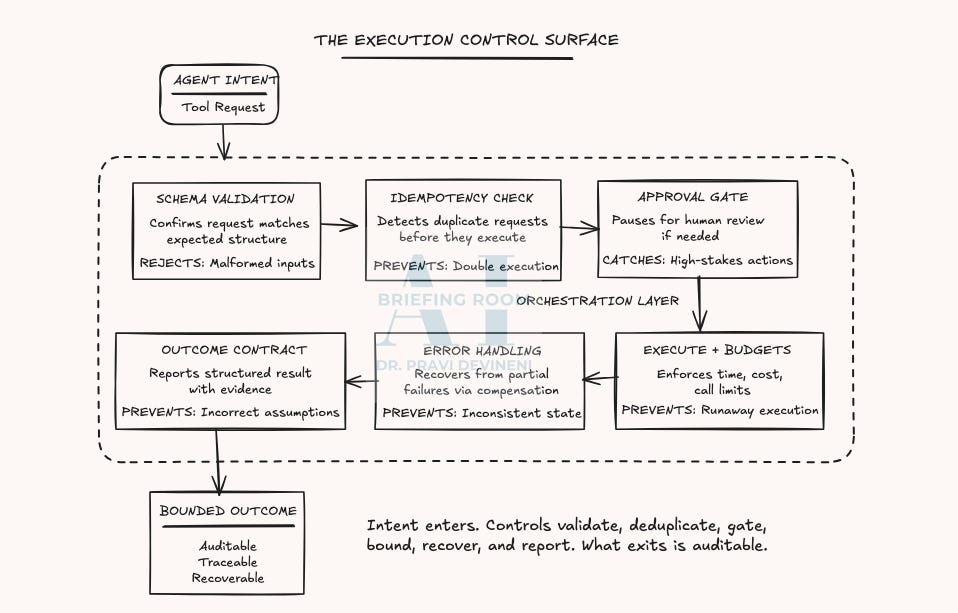
1. Schema Validation
Purpose: Stop malformed or out-of-contract tool requests at the orchestration boundary before they trigger downstream side effects.
Failure mode: Agent sends an update with the wrong record ID format → the system accepts it → the wrong record gets modified → the team discovers it later as “bad data” instead of a tool-call error.
Why it matters: Schema validation is the cheapest control you’ll deploy and the first one that matters. If malformed requests cross into execution, every subsequent control works with corrupted inputs. Debugging becomes expensive once bad requests reach execution.
Schema Validation Contract:
─────────────────────────────
Input: Raw tool request from agent
Output: { valid: boolean, errors: string[], sanitized_request: object }
Rule: If valid=false, request never reaches tool. No exceptions.Implementation checklist:
Every tool has a formal input/output schema (JSON Schema or equivalent)
Validation runs synchronously before execution
Errors are specific (field-level) and returned to the agent/orchestrator
Schema versions are tracked and compatibility is enforced
Nested objects/arrays have explicit types, constraints, and bounds
2. Idempotency
Purpose: Prevent retries from creating duplicate side effects when the same tool request is executed more than once.
Failure mode: Network timeout → orchestrator retries → the tool runs again → duplicate side effect (double payment, duplicate record, repeated notification) → impact is discovered later, after the fact.
Why it matters: Retries are a normal part of distributed systems. Without idempotency, every retry becomes a second write. Duplicate effects are expensive to detect and even harder to unwind.
Idempotency Contract:
─────────────────────────────
Request includes: idempotency_key (UUID)
Store checks: key → previous_result mapping
If found: Return previous_result, skip execution
If not found: Execute, store result, return resultImplementation checklist:
Each request includes a unique request ID (UUID) used to detect duplicates.
Keys are persisted and checked before execution
The idempotency key retention window (TTL) is defined and documented, so delayed retries are treated as duplicates.
Duplicate requests return the original response, not a new execution
Idempotency collisions/replays are logged and monitored as risk signals
3. Approval Gates
Purpose: Require human approval for actions that are irreversible, high-stakes, or exceed defined thresholds.
Failure mode: Agent tries to “fix access” → invokes a permission-change tool → expands permissions beyond intended scope → the change succeeds → security posture degrades → audit catches it later.
Why it matters: Some actions should not run end-to-end autonomously. Approval gates create a deliberate pause at the risk boundary so judgment can be applied before irreversible execution. They also create accountability: high-impact actions have a named human owner, not an anonymous automation path.
Approval Gate Contract:
─────────────────────────────
Trigger conditions: amount > $X
OR record_count > Y
OR criticality = HIGH
OR tool_category = PRIVILEGED # permission changes
Approval payload: { intent, request, context, risk_score, affected_resources, expires_at}
Outcomes: APPROVED → execute
REJECTED → cancel + notify agent
EXPIRED → cancel + escalateImplementation checklist:
Risk thresholds are defined per tool (dollar amount, record count, criticality)
Privileged tools are explicitly tagged (permission changes, admin operations)
Requests include intent, request details, affected resources, and risk signal(s) for decision-making
Requests expire if not approved within a defined approval window
Audit trail records who approved, when, and what they saw (accountability by design)
Threshold guidance: Start conservative and track approval outcomes over time, raising thresholds only after repeated evidence the agent stays within acceptable bounds. Too many gates create friction, but too few create incidents.
4. Error Handling & Compensation
Purpose: Recover cleanly from partial failures in multi-step tool workflows, so the system doesn’t get stuck in a half-completed state.
Failure mode: Step 3 of 5 fails → steps 1–2 already committed → the system is left inconsistent → manual cleanup is required → cleanup introduces new errors.
Why it matters: Multi-step execution creates real side effects. Without a rollback/compensation plan, a single failure can strand the system in an inconsistent state where it’s unclear what happened and hard to recover safely. Compensation turns partial failure into a defined recovery path.
Saga Pattern Contract:
─────────────────────────────
Operation: [Step A] → [Step B] → [Step C]
Compensation map:
A fails: No action (nothing committed)
B fails: Undo A
C fails: Undo B → Undo A
Rule: Compensation must be idempotent.Implementation checklist:
Every multi-step operation defines compensating actions per step
Compensation runs in reverse order to unwind dependencies cleanly
Compensation failures escalate to an incident queue so inconsistent state is visible and owned
Orchestrator tracks step completion status for all in-flight operations
The orchestrator supports an explicit reconciliation step that queries the system of record and resolves “unknown” outcomes before retrying or proceeding
5. Execution Budgets
Purpose: Enforce hard limits on resource consumption—time, cost, tool/API calls, retry/recursion depth, and records affected—to keep execution bounded.
Failure mode: Agent enters a loop → each iteration is individually valid → resource consumption grows without limit → costs spike / systems degrade / external services throttle you → the overrun is discovered after the fact.
Why it matters: Models don’t know when to stop without explicit controls. Execution budgets are the circuit breakers that transform "unbounded execution" into "bounded execution with defined failure mode.
Execution Budget Contract:
─────────────────────────────
Budgets: { max_duration_sec: 300,
max_cost_usd: 50,
max_calls: 100,
max_depth: 5,
max_records: 1000 }
On budget exhaustion:
- Halt current step
- Commit checkpoint
- Return partial result with budget_exhausted flag
- Log for reviewImplementation checklist:
Time budget: max execution duration per operation
Cost budget: max spend per operation (tracked in real time)
Call budget: max tool/API calls per operation and per time window
Depth budget: max recursion or retry depth
Record budget: max records affected per operation
Budget exhaustion triggers a graceful stop with a structured partial result
6. Outcome Contracts
Purpose: Return execution results in a structured form so agents and operators can verify what happened, what changed, what evidence supports it, and what to do next—so they can act safely.
Failure mode: Tool executes → returns “success” → the agent proceeds → the outcome was partial, conditional, or ambiguous → the next step assumes completion → errors cascade.
Why it matters: Outcomes close the loop. Without a contract, “success” becomes a guess, and agents fill gaps with assumptions. Outcome contracts make completion, partial completion, warnings, and ambiguity explicit.
Outcome Contract:
─────────────────────────────
status: COMPLETE | PARTIAL | FAILED | UNKNOWN
summary: one sentence of what happened
evidence: IDs / confirmation codes / timestamps
changes: what was created / updated / deleted
warnings: anything the agent must account for
next_step: retry | human_review | continueImplementation checklist:
Outcomes are returned in a consistent structure across tools
Partial and unknown outcomes are explicitly represented and handled by orchestration
Evidence is machine-verifiable (IDs, timestamps, confirmation codes)
Orchestrator uses outcome status to decide next action (retry, compensate, escalate)
Outcomes are logged and traceable end-to-end for audit and debugging
The Execution Controls Matrix
Use this matrix as a design and review checklist. For each tool, confirm which failure modes apply, then verify the corresponding control is implemented and enforceable.
In Closing
Execution is where governance becomes operational.
Every tool invocation carries an implicit contract: what the agent intends, what credentials it inherits, what the system will accept, and what happens when those assumptions break. The execution controls encode which actions can run autonomously and under what conditions.
Design-time execution controls prevent predictable failures, give operators clear intervention points, and make post-incident review actionable: which control failed, where it lives, and who owns it. Without them, failures are diffuse—hard to trace, harder to attribute, expensive to fix.
The next post focuses on the engineering implementation of these governance controls through specifications and contracts. Specifications define expected behavior, inputs, and outputs. Contracts formalize the handoffs between components, turning governance into auditable, maintainable infrastructure.







This piece realy made me think. Excellent connection to planning.