
The Agentic AI Playbook—Terminology
A Field Guide for Builders, Security, and Ops || Edition 19

This post is part 2 of the Agentic AI Series — a multi-part exploration of how autonomous systems are reshaping enterprise architecture, governance, and security.
The Short Version
Agent vs. Approach: Agentic AI defines the autonomous approach; the AI Agent is the specific entity running the goal-seeking loop, operating independently of a reactive Assistant.
The Agentic Loop: All agents follow the seven-stage cycle (Perceive → State → Plan → Evaluate → Act → Critic → Learn) that moves from context gathering to execution and self-critique.
Mandatory Controls: Autonomy demands specific security boundaries: Policy-Bound Planning, Non-Human Identities (NHI) for scoped access, and an Execution Sandbox to strictly contain the agent’s actions.
Traceability is Critical: Provenance tracks data sources while Observability links every plan step, tool invocation, and outcome for mandatory auditing and debugging.
Governance Surface: A consistent vocabulary creates the governance surface required by Security and Ops to define controls and reliably manage the risks inherent in autonomous systems.
Why This Vocabulary Matters
A customer submits a ticket requesting a refund. A chatbot would reply with the link to the refund policy. An agent connects three dots: the user’s loyalty tier, their lifetime value (LTV), and a failed refund transaction from two days ago. It checks eligibility rules, calculates an immediate store credit to preemptively address the issue, drafts a personalized apology, and executes the credit action.
That’s not conversation—it’s autonomous work. The agent perceives context, plans actions, evaluates options, and learns from outcomes. But every team describes these capabilities differently. Builders talk about “tool chains,” security says “privilege boundaries,” and ops wants “traceable decisions.”
This glossary establishes shared language for what agents do and where to place controls.
The Agentic Loop (At a Glance)
Perceive → State → Plan → Evaluate → Act → Critic → Learn
LLMs generate text. Agents execute workflows. Wrap the model with tools, memory, policy, and identity, and you get software that can pursue goals—safely, traceably, and iteratively better.
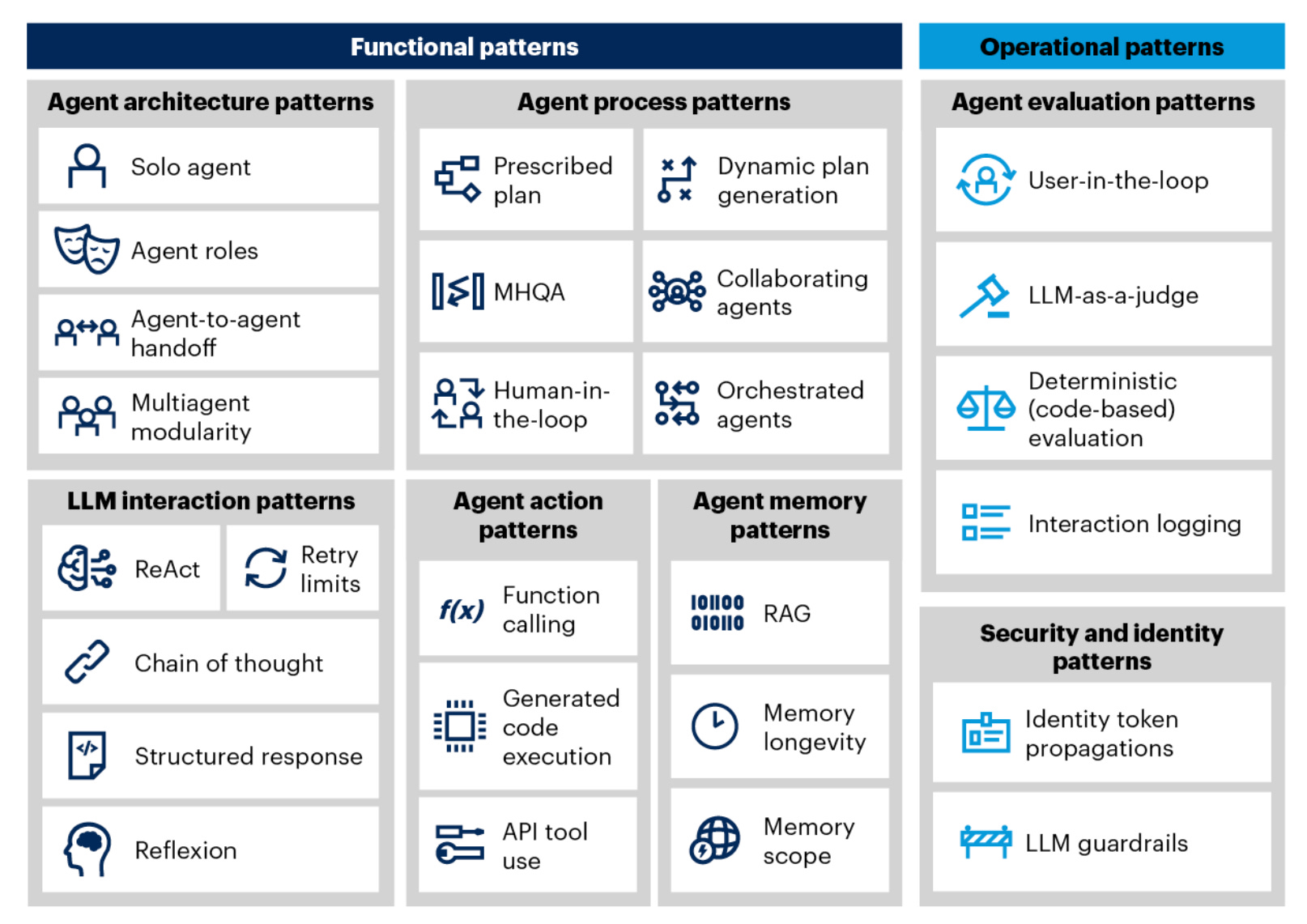
Foundation: What Is an Agent?
Agentic AI (The Approach) An approach to building AI solutions using software entities that exhibit autonomy, goal-seeking behavior, and adaptive decision-making. It represents a continuum from simple task automation to fully autonomous systems.
AI Agent (The Entity) Software that perceives its environment, decides what to do next, acts on those decisions, and improves over time with limited human direction. It operates independently of chat interfaces or explicit user commands for each step.
AI Assistant A reactive interface that waits for explicit instructions and executes them. It lacks the autonomy to pursue goals independently.
Why the distinction matters: Autonomy requires authorization scopes, execution budgets, and rollback mechanisms that request-response systems don’t need. The governance model changes fundamentally when software initiates its own actions.
Anatomy of the Agent Loop
The following sections define the core stages of the agent’s operational cycle, moving from context gathering to autonomous action and learning.

1. Perceive (Gather Signals)
How the agent collects context from its environment—APIs, logs, documents, sensors, event streams, or user inputs.
Retrieval-Augmented Generation (RAG) The technique of fetching authoritative data to ground the agent’s reasoning in current, verified facts, turning the system into a dynamic platform that can reason over fresh information without retraining
Provenance Recording where each piece of information originated, when it was collected, and through what process. Essential for debugging decisions and maintaining audit trails when agents make consequential choices.
Prompt Hygiene Sanitizing of inputs to strip out embedded instructions or adversarial content that could hijack agent behavior. Treats external data as untrusted by default, preventing injection attacks from compromised sources.
Example: Agent ingests the support ticket, user’s order history and loyalty tier, plus real-time refund transaction status—recording provenance for each source.
2. State (Build Context)
What the agent believes is true right now—a structured snapshot of entities, relationships, timestamps, and confidence levels.
Context Package The structured, interpreted artifact containing the agent’s current understanding of relevant conditions, which is used as the foundational input for the planning phase.
Temporal Reasoning Understanding time relationships that affect decisions—how long ago something happened, how urgent something is, and what sequence of events led to the current state.
Example: “Order #8921 initiated 72 hours ago; refund window closes in 24 hours; user is Gold Tier with high Life Time Value; refund eligibility assessed at 98% confidence.”

3. Plan & Evaluate (Decision Generator)
This mechanism translates desired outcomes into executable sequences of actions and rigorously validates the feasibility and safety of that proposed plan.
Action Sequence Generation
Tool Catalog The complete, accessible list of functions and capabilities the agent is authorized to invoke in the environment. This represents the agent’s vocabulary of executable verbs, such as check inventory or process refund.
Planner The component that selects which tasks to invoke, determines their sequence and dependencies, and constructs a step-by-step workflow for the agent to follow.
Subgoal Decomposition Breaking of complex objectives into intermediate milestones that can be achieved independently, which are then composed into a complete solution.
Example: “Verify eligibility → Calculate final amount → Draft email → Initiate refund API call.”
Policy and Fitness Vetting
The validation layer that evaluates whether a proposed plan is good enough to execute.
Goal The desired end state that defines success for the agent, which is not just the task to complete, but the outcome to achieve (e.g., maximizing customer satisfaction).
Value Function The component that scores a proposed plan across multiple dimensions—including expected effectiveness, resource cost, execution time, risk level, and compliance—to determine if the plan is actually good.
Policy-Bound Planning Building permissions, budgets, and safety constraints directly into the planning process, ensuring the planner only considers actions within policy bounds.
Example: “Proposed plan meets 1-hour service goal; cost is zero; risk score 0.01; complies with refund policy (Policy ID 42B). Green light for execution.”

4. Structured Reflection (Pre-Action Critique)
The self-critique phase where the agent examines its own reasoning before committing to action.
Chain of Thought (CoT) Articulating reasoning step-by-step rather than jumping to conclusions, which makes the logic visible for debugging and empirically improves performance on complex reasoning tasks.
Tree of Thoughts (ToT) An advanced reasoning pattern that explores multiple solution paths simultaneously, evaluates promising branches, prunes dead ends, and converges on the optimal approach through systematic exploration.
Structured Response Constraining LLM outputs to strict formats like JSON or XML schemas, which is essential for ensuring that downstream orchestrators can reliably parse and validate the agent’s actions programmatically.
Example: Agent generates the refund amount, uses CoT to confirm the calculated amount matches order history minus applied discount, and formats the plan into structured JSON for the orchestrator.

5. Act (Execute Within Bounds)
Taking action in the real world—within carefully defined scope and audit boundaries.
Tool Calling The pattern where the reasoning engine requests execution of specific functions with typed parameters, defining the boundary between reasoning and doing after the orchestration layer executes the functions and returns results.
Non-Human Identities (NHI) Machine credentials—such as API keys, service accounts, and certificates—that agents use to authenticate to external systems, and which must have scoped, time-limited permissions.
Model Context Protocol (MCP) A standard interface specification for how tools advertise their capabilities and how agents invoke them, enabling interoperability across different agent frameworks without custom integration code.
Execution Sandbox A confined runtime environment with resource limits and policy enforcement that strictly contains the agent’s actions, preventing it from executing anything outside its authorized system scope.
Shadow Mode Operating the agent with full reasoning and planning capabilities but without actually executing state-changing actions, which is critical for validating behavior in production conditions before granting write access to real systems.
Example: Agent calls Refund.process using an NHI scoped to refunds under $1,000. In shadow mode, the call is logged but not executed.
6. Outcome Audit (Post-Action Critique)
Evaluating outcomes based on observed effects in the environment, not just API success codes.
Post-Action Verification Confirming that the intended outcome has been achieved and that the environment is in the expected state, which requires validating the observable effects beyond a simple API success code.
Output Attestation Creating signed, immutable records that document exactly what actions were taken, by which identity, at what time, and under what authorization, providing non-repudiable evidence for compliance and forensics.
Observability (Output) Instrumentation that links plan steps, tool invocations, state changes, and outcomes into a queryable graph, which enables operators to trace decisions back through the full reasoning chain.
Example: “Refund transaction ID 5476 confirmed at 16:01:22 UTC; customer notified successfully; output attestation generated; execution trace available in span ID XZY987.”
7. Learn (Retain for Next Time)
Converting experience into improved capability through structured memory.
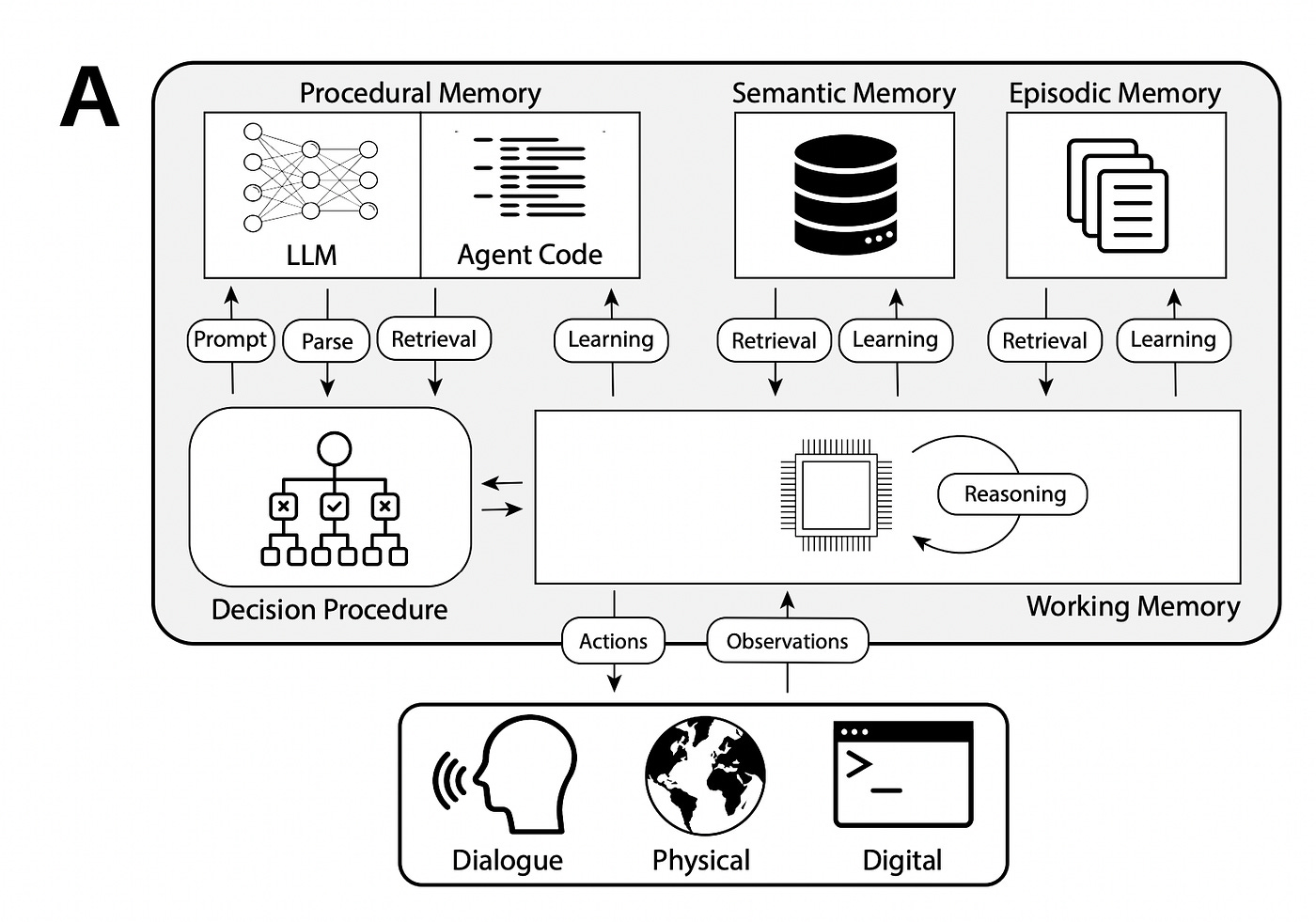
Memory Element The storage layer responsible for retaining information across agent invocations, housing short-term memory for the current task context and long-term memory for learned behaviors.
Episodic Memory Record of specific events (what happened, when, with what result) that stores concrete experiences to prevent the repeating of known failures.
Semantic Memory Domain knowledge, policies, and factual information accessed as authoritative reference material, typically read-only and sourced through RAG.
Memory Scope Classification of who can access what memory—Local, Shared-User, Shared-Agent, or Global—which determines both privacy boundaries and coordination capabilities.
Example: System stores “User X requested refunds twice in 30 days for wrong-color items.” Future orders for User X trigger extra inventory verification.
Rule of thumb: If you can’t clearly articulate what information is being remembered, who can access it, and how long it persists, you can’t govern the memory system responsibly.
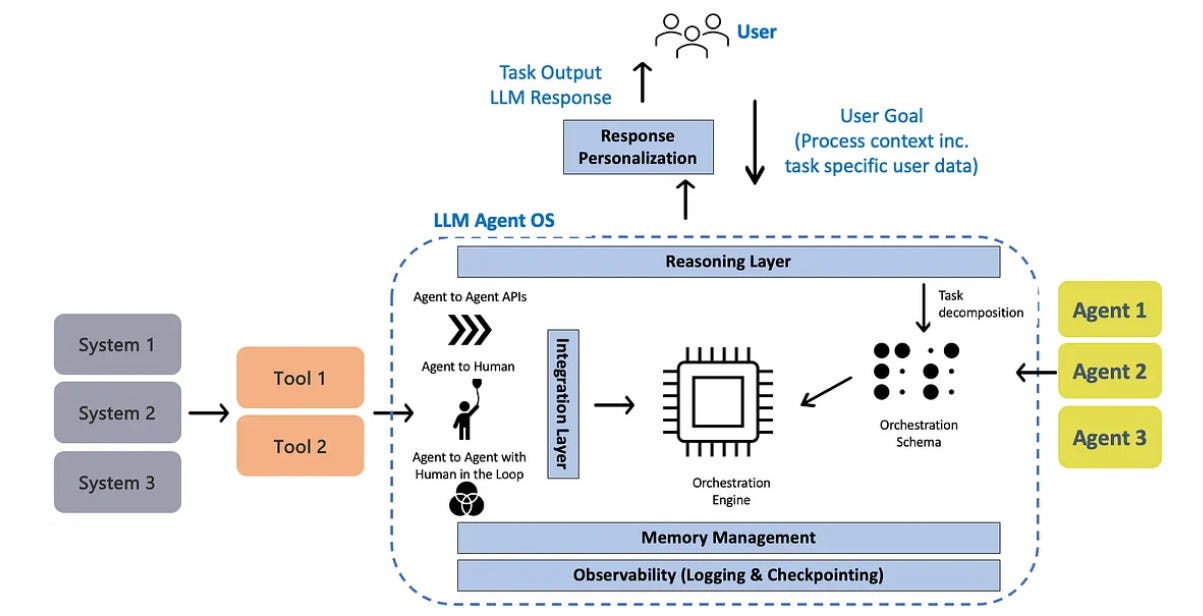
Multi-Agent Patterns
Solo Agent A single agent that handles all aspects of a task—perception, planning, execution, and learning—making it simpler to build, debug, and operate, but limited in scale.
Multi-Agent Systems (MAS) Architectures that decompose capabilities across specialized agents, such as a Planning Agent, a Research Agent, and a Transaction Agent.
Orchestrated vs Collaborating Orchestrated systems use predefined workflows (e.g., Agent A always passes to Agent B), whereas Collaborating systems negotiate task allocation dynamically (e.g., agents bid on unassigned tickets).
Agent-to-Agent Handoff The contract between agents when transferring work, defining what context is passed, what authority is delegated, and what constitutes successful completion.
Human-in-the-Loop (HITL) Mandatory approval gates at high-stakes decision points, such as approving refunds over a high dollar threshold or granting irreversible account changes.
Coordination principle: Always label ownership. In orchestrated systems, the planner typically owns the complete workflow. In collaborative systems, ownership can shift mid-execution, which means accountability mechanisms must be equally dynamic.
Operations & Deployment
Guardrails Validation layers that enforce safety and policy boundaries on both inputs and outputs, implemented through techniques like schema checks, PII detectors, and behavioral monitors.
Alignment The continuous process of ensuring an agent’s goals and behavior are consistently safe and adhere to established human values, policy, and organizational objectives.
Identity Propagation The security enforcement mechanism preserving the human user’s identity and entitlements as the agent acts on their behalf, ensuring the agent never has more privilege than the user who initiated the task.
Observability / Traceability The capability to reconstruct the full chain of reasoning and action after the fact, which is essential for debugging autonomous behavior and maintaining accountability.
Agent Evaluation Measuring the long-term, reliable performance of the agent against its assigned goals, typically assessed through model-based scoring, user feedback loops, and business metrics.
Latency & Token Cost Critical operational constraints caused by agents chaining multiple reasoning cycles, tool calls, and reflection loops into sequential workflows, making them slower and more expensive than single-turn interactions.
Operational principle: If you cannot replay what the agent perceived, believed, planned, and executed—with timestamps, identities, and full context—you cannot operate it reliably in production or debug it effectively when problems occur.
In Closing
Operationalizing autonomous systems depends less on the complexity of the models and more on the clarity of the execution environment. You don’t need a massive lexicon, but rather a consistent set of terms used by every team—from development to security.
A shared vocabulary is the governance surface that allows architects to define boundaries, security to place mandatory controls (like Non-Human Identities and Execution Sandboxes), and operations to trace root causes, moving the focus from debating definitions to reliably managing the system’s autonomy in production. This consistency is the foundation of trust for any autonomous workforce.
Brilliant breakdown; I'm left wondering if the agent's 'learn' phase could predict complex future problems, truly anticipating diverse user needs.