
Closing the GenAI Divide: Execution Discipline for Scaling AI Pilots
Building the organizational muscle that turns AI pilots into durable, governed products || Edition 14

The AI Scaling Framework: Post 3 of 4 | [The GenAI Divide]
A playbook for selecting, scaling, and sustaining AI in the enterprise
The Economics of AI Risk: Why Foundations Matter More Than Speed
Closing the GenAI Divide: Execution Discipline For Scaling AI Pilots (this post)
Governing AI at Scale: Why Sustained Value Demands More Than Deployment
The Short Version
Start with a system map, not a model. Clarity beats speed—define how data, models, people, and decisions connect before you build.
Fix expertise gaps early. Cross-functional pods with product, ML, data, risk, and change management are what turn pilots into real products.
Build pipelines that govern themselves. Testing, monitoring, and approvals should flow inside the system, not around it.
Scale safely, not suddenly. Use testing groups, canary rollouts, and rollback rehearsals to learn before risk multiplies.
Treat AI as a living system. Mature it slowly through monitored feedback, retraining, and trust-building, not one-time launches.
Why 95% of AI Pilots Never Reach Production
AI doesn’t fail in the lab. It fails in the org chart.
Pilots that dazzle in isolation often collapse when they meet real data, real users, and real time. What fails isn’t the model — it’s the connective tissue: pipelines, ownership, and feedback loops that keep AI synchronized with a living business.
Leaders often scale AI like software — add servers, add users, add load. But AI scales non-linearly. Each new dataset, behavior, and policy change multiplies maintenance debt. The result is familiar: a graveyard of stale models — technically sound, operationally abandoned.
In AI, the finish line isn’t deployment. It’s durability.
This post is the how-to: the practices that turn promising pilots into production-ready systems.
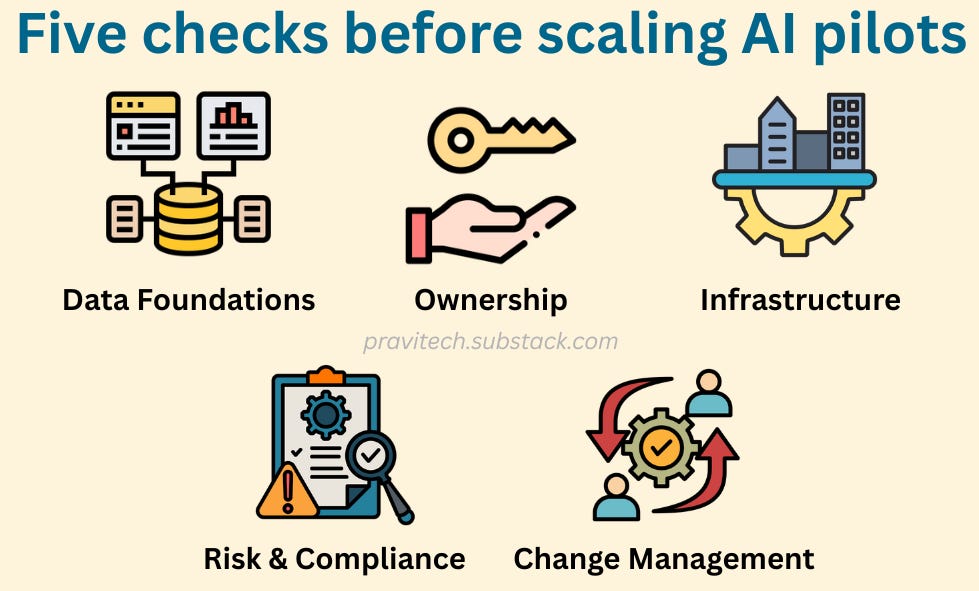
The AI Readiness Check: Before You Scale
Execution discipline begins before scale. The readiness check isn’t paperwork — it’s how you spot the cracks that widen under real load.
Data Foundations — Is the system ready to feed itself?
Data must be reliable, owned, refreshable, and monitored for drift from day one.
Ownership — Are roles and accountability defined?
Product, model, and operations leads must be named and funded before scale.
Infrastructure — Can you deploy and roll back safely?
Testing, deployment, and rollback environments must exist and be rehearsed.
Risk & Compliance — Are approvals built into the process?
Privacy, legal, and security reviews must clear before launch — not after issues surface.
Change Management — Are people ready for the system to land?
Training, workflow adjustments, and communication plans must align with the AI lifecycle.
With foundations confirmed, sequence the work across the lifecycle so each decision reinforces the next.
The AI Execution Lifecycle
Design & Alignment: Clarity, ownership, dependencies
Do we know what we’re building and who owns it?
Build & Integrate: Quality, security, governance
Can we build safely, traceably, and repeatably?
Validate & Launch: Reliability, safety, control
Can we deploy incrementally and learn safely?
Operate & Mature: Sustained value, learning loops
Can we keep it improving without breaking trust?
Eight Practices for Sustainable AI at Scale
Most AI failures aren’t technical — they’re organizational. These practices build the muscle that turns fragile pilots into durable products.
1. Map the AI System End-to-End
Execution discipline starts with understanding what you’re building. Start with a system map — one artifact linking data sources, models, APIs, and business outcomes.
Every node should answer:
Who owns it?
What’s the data lineage?
Where does governance apply?
What’s the rollback path?
Without this map, dependencies stay hidden until failure propagates. With it, you can staff properly, plan recovery paths, and allocate risk. This blueprint guides every decision that follows — funding, staffing, governance, and tolerance for failure.
Once dependencies are visible, put stable ownership around them.
2. Close the Expertise Gap with Core AI Delivery Teams
Scaling requires a core execution pod that owns delivery end-to-end:
Product Owner: connects model outputs to measurable business value
ML Engineer: maintains pipelines, monitoring, and retraining triggers
Data Steward: ensures legal and operational data quality
Risk Lead: embeds policy and compliance guardrails in-pipeline
Change Manager: coordinates user training and adoption
This replaces the “throw-over-the-wall” handoff between data science and operations.
Execution discipline starts with stable, cross-functional ownership.
With owners in place, give them rails that make good practice the default.
3. Build Fast, Governed Pipelines
AI needs purpose-built pipelines where governance is an ingredient, not an overlay. Five continuous tracks define the minimum viable flow:
Data Ops: ingestion, labeling, versioning — provenance validation & consent checks
Model Ops: training, validation, packaging — fairness & robustness tests per build
Feature Ops: embedding & reuse — ownership logs & access audit trails
Eval Ops: synthetic + real-world testing — peer review & drift-triggered retraining
Deploy Ops: rollout + rollback automation — risk & compliance approvals before promotion
Execution discipline means these tracks run as one governed pipeline, not five separate toolchains.
Every model that ships should produce a traceable audit artifact (code hash, data lineage, test logs, performance benchmarks, approvals). When governance is embedded, reviews become evidence generation, not bureaucracy.
Strong rails need strong edges — secure them early.
4. Design for Security and Safety from Day One
AI systems introduce unique attack surfaces—from prompt injection to data poisoning to model extraction. Security can’t be retrofitted; it must be secure by design.
Essential guardrails to build in:
Input validation: Sanitize prompts, enforce token limits, block malicious patterns before they reach the model.
Output filtering: Screen responses for sensitive data leakage (PII, credentials, proprietary info) before display.
Access controls: Implement least-privilege principles—users and systems get only the minimum model access they need.
Rate limiting: Prevent abuse through automated request throttling and anomaly detection.
Model isolation: Separate production models from training/experimentation environments with network segmentation.
Audit logging: Capture every input, output, and decision with immutable logs for forensic analysis.
Treat every AI component like an exposed API, because it is. Treat AI security like application security: threat model early, pen-test regularly, patch vulnerabilities fast.
Security isn’t a gate at the end—it’s a design principle embedded in architecture, data flows, and deployment patterns.
With edges secured, prove readiness under real-world pressure — before full exposure.
5. Institutionalize Core Testing Groups
Before wide release, route each model through a core testing group mirroring real operational diversity: domain experts, frontline users, and risk reviewers across business lines.
Mandate: pressure-test under realistic conditions — edge cases, ambiguous data, hostile prompts, regulatory scenarios. Think of it as an internal red team feeding retraining and rollout gating. It’s faster (and cheaper) than learning from production incidents.
When the tests pass, scale exposure the safe way in slices.
6. Use Phased Rollouts to Manage Risk in Production
AI rarely fails gracefully. Scale with phased rollouts — progressive exposure where a small subset of users or transactions see the model first.
Key patterns:
Shadow Mode: model runs beside human decisions to compare outcomes
Partial Routing: 5–10% of traffic uses the AI output
Auto-rollback: preset thresholds trigger instant reversion
Controlled exposure is the only way to scale safely.
Then give the system time to harden under real conditions.
7. Respect AI System Maturation Time
AI products harden through iteration. Set a defined maturation window, typically few to several months, before calling a system “steady state.”
During that period:
Retraining cycles follow a schedule
Evaluation datasets evolve with new edge cases
Ownership metrics (accuracy, drift, uptime) stabilize
Maturation time isn’t slowness — it’s controlled learning. Organizations that rush this window pay for it later in reliability debt.
Finally, anchor execution in the cadence of the business.
8. Tie Execution Back to Business Readiness
Execution discipline must connect directly to enterprise rhythm: budgeting, operations, risk reporting. Use three recurring rituals:
Quarterly AI Portfolio Review — performance, incidents, cost of sustainment
Monthly Model Health Report — accuracy, drift, retraining status
Annual Maturation Audit — lessons learned, retirements, next-gen upgrades
These checkpoints turn execution into an ongoing business process, not a one-time rollout.
In Closing
Pilots prove possibility; execution proves durability.
Closing the GenAI divide isn’t about bigger models or better demos—it’s about execution discipline, the organizational muscle that turns pilots into products users can trust.
When you map the system, staff the pod, run governed pipelines, secure the edges, test with real users, scale in phases, allow maturation, and sync with the business cadence, pilots evolve predictably, governance moves with velocity, and adoption becomes a feature, not a fight.
The organizations that win AI transformation won’t be those who scaled first, but those who scaled with discipline—turning fragile experiments into durable systems that earn trust, adoption, and return on investment.
Great read, Dr. Pravi! Have you found organizations still pushing back on having internal test teams? That was a highly contested issue early in my career. I'm wondering if AI has changed the general perspective.