
Bias by Design: How Data Quality Creates Foundational AI Risk
Why training data curation and representation are critical for building trustworthy AI systems || Edition 6

AI Risk Series: Post 2 of 6 | [Executive briefing]
Each stage of the AI lifecycle introduces risks that amplify each other if left unmanaged.
The Series: Compounding Risks in AI Systems
The Wrong Question: Why AI Risk Starts with Misaligned Goals
Bias by Design: How Data Quality Creates Foundational AI Risk
Drift Happens: How AI Systems Degrade Over Time in Production
Your AI Model Is Under Attack: New Security Threats to AI Systems
No One’s in Charge: How Poor AI Governance Amplifies Every Risk
The Problem: Bias Is Designed In
Biased facial recognition systems sold to law enforcement. Flawed credit models used to allocate opportunity. Both hailed as innovations — until real-world tests revealed just how deeply bias was wired into their design.
These weren't rogue failures. They weren't caused by "bad AI." They were the predictable outcome of biased data pipelines — where underrepresentation, shortcut labeling, and poor validation quietly lock inequities into the foundation of a system.
The goal misalignment covered in Post 1 of the AI Risk Series often drives the data bias patterns explored here—when organizations choose wrong metrics, they collect wrong data.
Case 1: Facial Recognition and the Cost of Being Invisible
In 2018, Joy Buolamwini and Timnit Gebru's Gender Shades study tested commercial facial recognition systems from leading tech companies.
Systems had near-perfect accuracy for white men — but error rates soared to 34% for dark-skinned women.
The gap wasn't random. It reflected who was (and wasn't) in the training data. Darker-skinned women were among the least represented groups.
Despite this, the systems were actively marketed to law enforcement. Police agencies were sold tools that worked worst on exactly the populations most vulnerable to surveillance harms.
The problem wasn't just technical. It was institutional: biased datasets passed as "good enough," validation ignored subgroup accuracy, and no governance mechanism existed to ask whether deployment into policing was appropriate at all.
Bias wasn't an accident. It was designed in.
Case 2: Credit Models and the Economics of Exclusion
AI-driven credit scoring has been celebrated as a way to expand financial access. But biased data tells a different story.
Loan approval models trained on historical repayment data often penalize marginalized groups, because past systemic inequities (redlining, income gaps, fewer formal credit records) are embedded in the dataset.
A model "learning from history" learns to reproduce exclusion.
The consequence: applicants from disadvantaged groups are systematically denied loans or offered worse terms — not because of present ability to repay, but because the data reflects a biased past.
This isn't just unfair. It compounds inequality. Those denied credit lose opportunities to build wealth, making it even less likely their data will reflect "creditworthiness" in the future.
When access to capital is the gateway to opportunity, data bias becomes economic bias at scale.
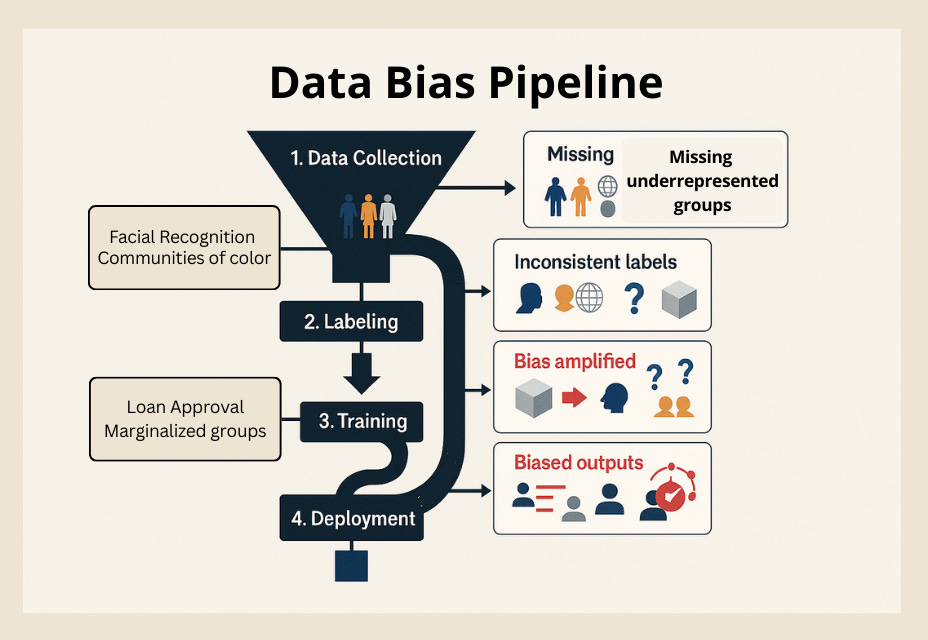
The Short Version
Problem: AI systems don't start unbiased and "become" biased. Bias is baked in from the moment data is collected, labeled, and transformed. Once embedded, it cascades downstream into training, deployment, and real-world harm.
Solution: Build bias testing, documentation, and accountability into every stage of the data lifecycle. Assume bias exists — then prove where and how it's being mitigated before trusting outputs.
Why Bias Creeps In
Bias enters the pipeline long before the model is trained:
Data availability: Historical data reflects who was visible and recorded — and who was not.
Labeling shortcuts: Annotators bring assumptions and inconsistencies.
Sample bias: Data skews toward urban centers, frequent users, or majority groups.
Validation gaps: "Average accuracy" hides subgroup failures until real harm emerges.
Every step is an opportunity for inequity to harden into "ground truth."
Five Critical Questions for Data Integrity
The difference between biased and representative AI often comes down to asking the right questions at the right time. These five target the critical checkpoints where bias typically enters.
Who is missing from the data?
Which groups are underrepresented or invisible?
How consistent are the labels?
Do annotators agree, and what assumptions shape their judgments?
Is the sample representative?
Statistical tests should validate population-level representativeness before training.
How are transformations tracked?
Document data lineage and provenance from raw input → features → model output.
What subgroup outcomes are validated?
Performance must be tested and reported across demographics, not just in aggregate.
Remember: "Acceptable" error rates may be different for different groups—make these trade-offs explicit and get proper approval

How to Audit Bias — By Role
If you're building AI (data scientists, engineers, developers)
Diversify annotators and track inter-annotator agreement
Demand representativeness tests at every lifecycle stage
Document lineage and provenance as a gating step
If you manage AI projects (product managers, delivery leads)
Require bias audits before funding or deployment
Set explicit thresholds for subgroup performance
Make documentation of data pipelines mandatory artifacts
If you govern AI systems (risk managers, compliance officers)
Treat bias as a lifecycle risk, not a post-hoc compliance task
Require evidence of representativeness and lineage
Build accountability frameworks for ongoing bias monitoring
If you're affected by AI (users, community advocates, stakeholders)
Demand transparency in what datasets represent and exclude
Push for opt-outs and independent oversight mechanisms
Advocate for inclusion in data collection and review processes
The Economic Reality
Biased AI creates cascading institutional and legal costs. When facial recognition systems fail disproportionately for women and minorities but are sold to law enforcement as "accurate" tools, the consequences compound: wrongful arrests generate lawsuits, bias scandals trigger contract cancellations, and regulatory backlash can eliminate entire markets overnight.
Institutional liability: Organizations deploying biased systems face legal challenges, regulatory fines, and loss of public trust when bias is exposed in high-stakes decisions.
Existential market risk: Companies that build representative AI from the start avoid both the immediate costs of bias and the risk of their entire product category being banned—as facial recognition vendors learned when cities began prohibiting their systems.
Fixing bias after deployment costs exponentially more than building inclusive systems from the beginning.
The Economic and Social Cost of Biased Data
Fixing bias upstream may seem expensive — diversifying datasets, hiring auditors, slowing deployments. But ignoring it costs more:
For law enforcement: wrongful arrests, lawsuits, loss of public trust
For financial services: regulatory penalties, reputational damage, systemic exclusion
For enterprises: wasted investment when biased systems must be scrapped and rebuilt
Bias compounds because data compounds. Once embedded, every downstream model and decision amplifies the harm.
When Bias Mirrors Bigger Systems
Not all bias can be solved with better sampling. Some reflect structural inequities that individual organizations can't solve alone. Healthcare cost data mirrors inequities in access and insurance coverage; policing data reflects decades of over-surveillance in specific communities. Fixing these requires systemic solutions — regulation, policy reform, and new incentive structures that extend beyond individual organizations.
In Closing
The saying is familiar: a model is only as good as its data. But when the data is biased, the model isn't just "bad." It becomes a multiplier of inequity.
Yet data bias rarely acts alone. Unchecked, it locks in design vulnerabilities (the focus of our next post on system architecture), accelerates drift, and amplifies inequities downstream. Governance isn't just oversight — it's how organizations break this compounding cycle before biased data becomes embedded in production systems that are expensive and difficult to fix.
Bias by design means risk by design. If we want AI that works as intended — for everyone — we must treat data integrity as the foundation of trustworthy systems.